Oui, « UX Research DIY » ça aurait fait péter les scores sur twitter, mais décidément j’ai du mal avec les anglicismes et les acronymes. Donc l’idée que j’ai voulu tester, c’est de montrer qu’on peut faire de la recherche utilisateur avec les moyens dont on dispose, sans nécessairement avoir des connaissances techniques ou passer par un service payant.
Dans ce premier article, je vais plus parler des choix, des difficultés, des limites et du résultat global. Dans un deuxième article je ferai une analyse plus fine des résultats en comparant si possible avec d’autres recherches plus scientifiques.
La problématique
J’avais une problématique relativement simple. Je travaille sur un projet d’abonnement dématérialisé pour un opérateur de téléphonie. Dans une des étapes du processus, l’utilisateur doit saisir des informations présentent sur sa carte d’identité ou son passeport. Ces informations dont sous la forme d’une MRZ (Machine Reading Zone) par exemple « 07385167754<9 » qui est donc conçue pour les machines et non pour les humains. Il y a notamment de chevrons qui remplacent les espaces, tout est en majuscule, etc…

Explication de la bande MRZ
Dans le projet, les personnes chargées de la fraude veulent limiter le nombre de saisie. Même si je ne suis pas très d’accord avec leur raisonnement (Il est facile de concevoir un faux numéro et donc un fraudeur ne va pas tester plein de numéros), ça m’arrange aussi parce que si l’utilisateur fait trop d’erreur, il y a un moment où il faut l’aider à continuer.
Donc la question était de savoir quel était le taux d’erreur pour la saisie de ce type d’informations et l’on pourra en déduire un nombre maximum d’essais raisonnable. Mais les erreurs peuvent survenir à plusieurs moments, soit la personne a mal identifié la suite de caractères à copier, soit elle est n’arrive pas à les lires (Par exemple entre 0 et o), soit elle fait des erreurs dans la saisie.
Donc ce que je voudrais obtenir c’est un taux d’erreur en fonction de la longueur du champ et la présence ou non de chevrons.
Mise en place et diffusion
Pour cette première étude, j’ai choisi l’outil le plus simple, le plus facile à mettre en œuvre pour faire un formulaire : Google drive.
J’avais pensé un moment générer des images pour chacun des codes à saisir, mais les formulaires Google ne permettent pas de les intégrer proprement au-dessus de chaque champ de saisi. L’image serait donc séparée du champ ou positionné au-dessous. Je n’ai pas trop exploré les possibilités, mais ça m’a rapidement semblé bancal, donc je me suis résolu à plus simple : Du texte rien que du texte.
J’ai rédigé une consigne succincte vu que l’exercice est simple en précisant qu’il faut saisir les informations « à la main » et non les copier/coller. Je choisis une saisie par écran pour éviter les confusions et c’est une démarche classique. Comme j’ai 3 longueurs de champs différentes et que je veux rester sur un nombre de saisies raisonnables, je fais 3 essais par champs donc au total 9 saisies par utilisateurs.
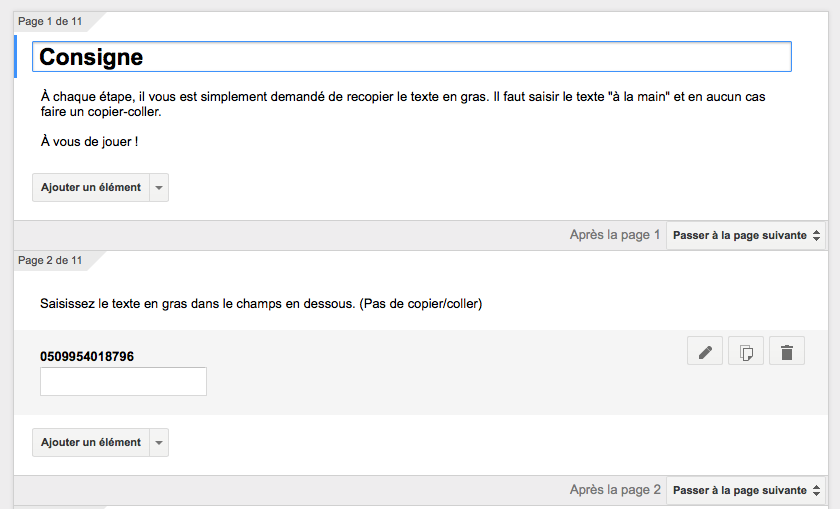
Formulaire google
En deux heures maximum mon questionnaire était en place, prés à être publié. J’ai diffusé l’adresse sur Twitter et sur la liste ergoIHM.
Réponses
Je me disais avec 1000 personnes sur twitter et 2500 sur ergoIHM, ça fait un gros du 3000, avec un taux de retour de 3 ou 5 %, au tout début août dans la semaine la plus creuse de l’année, j’aurai une centaine réponses ou au mieux 200 en relançant deux ou trois fois.
Premier enseignement, le nombre de réponses a été au-delà de toutes mes espérances. En deux heures, j’ai eu plus de deux cents réponses. J’ai arrété le questionnaire le lendemain soir, donc après une trentaine d’heures avec 349 réponses soit 3 141 saisies.
La consigne que j’avais faite était relativement simple. Je pense a posteriori qu’elle était trop simple et que les utilisateurs ne l’ont pas tous en mis en application. Comme j’ai eu très vite les premières réponses, mais très très vite (moins d’une minute), j’ai eu un doute, puis quelques tweets plus tard, je me suis aperçu qu’il était très tentant de copier/coller réponses, ce qui enlevait tout l’intérêt de l’expérimentation. Donc au bout de 2h30, j’ai modifié le questionnaire pour renforcer le message concernant la nécessité de saisir manuellement et j’ai rajouté une question à la fin « Avez vous utilisé le copier/coller pour répondre à ce test ? ». Sur les 124 réponses reçues après la modification, 6 utilisateurs ont déclaré avoir utilisé le copier/coller.
Deuxième enseignement, vos utilisateurs sont aussi feignants que vous ! Ils ne lisent pas les consignes ou du moins ne les appliquant pas toujours et cherchent la facilité. Il faut donc prévoir une consigne directive et ne pas hésitez à la répéter dès que c’est nécessaire. Mais dans leur grande majorité, ils font ce qu’on leur demande de leur mieux.
À noter que l’utilisation d’images aurait évité que le problème se pose. Je vais donc aussi regarder s’il y a un effet entre avant et après le changement de consigne.
Il y a bien sur quelques non-réponses (vide ou « qsdfqsf » ) qui devront être supprimées avant de traiter le questionnaire, mais c’est de l’ordre d’une dizaine donc là rien de surprenant.
Les résultats
Les réponses sont données sous la forme d’un tableau de données qui il est possible d’exporter pour les traiter dans Excel ou Numbers.
Dans le cas présent, il va falloir :
– Supprimer les non-réponses
– Utiliser quelques formules bien choisies pour calculer le taux d’erreurs.
– Comparer les taux d’erreurs suivant les différents cas.
– En tirer des conclusions.
– Comparer les résultats obtenus avec ceux d’autres études afin d’avoir une idée de la validité de cette méthodologie.
La première impression est donc quand même très positive en terme d’efficience : temps de mise en œuvre / nombre de résultats / qualité des résultats.
Suite au prochain épisode !
Hello Raphaël, merci pour ce post super intéressant qui me fait vraiment penser à une conférence donnée par Tomer Sharon @Google https://www.youtube.com/watch?v=9TJTbRw4ri8.
J’ai testé également cette méthode pour obtenir pas mal de réponses. ça a bien marché… mais ne crains-tu pas un épuisement de tes répondants à un moment ? Parce que je ne sais pas trop comment gérer ça et que ton expérience m’intéresse